
Introduction:
InnoDB has concept of history length that represents number of undo logs (or rollback segments) that has pending purge. It is necessary to understand why this variable should be tracked and what effect it has on overall transaction processing. But just tracking history length is not enough. Once user discovers that is is higher than expected then what steps user should take in order to curb this are equally important.
In this article, we will take a look at the all the related aspects including how this history length comes into play, how we can optimize it to keep it under check, etc. We will also run some real benchmark to understand effect of different observations we make.
Understanding Isolation Level
MySQL is relational database and complies with ACID requirement. “I” that stand for ISOLATION dictates how parallel running transactions sees the changing state of the data. Let’s first understand different ISOLATION LEVEL.
1. SERIALIZABLE:
a. As name suggest, it serializes transactions. If 2 independent transactions are trying to access same set of data then the first transaction to see the data will grab an exclusive lock on the data and all upcoming transactions will have to wait even for accessing the data (READ).
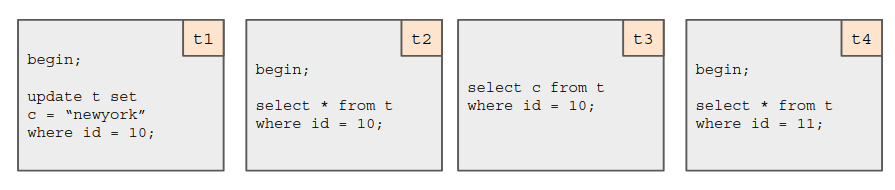
b. In the example below we have 4 transactions t1, t2, t3 and t4.
- Say t1 is first to start. It will place lock on said row with id = 10.
- t2 is trying to access locked row so it will have to wait (this is seralizating the transaction).
- t3 is also trying to access locked row but t3 is allowed to proceed as it is read-only transaction with single statement. t2 though readonly as this point in time may make modification in future as transaction is still open. So t2 read is blocking.
- t4 is allowed to proceed too since it is accessing different row (non-locked) from same table though.
c. This is most restrictive mode of operation and pretty easy to understand. A resource is accessible to only 1 transaction at given time. Of-course this limit the parallel operation as is not widely in use.
2. READ UNCOMMITTED:
- As name suggest, under this mode, transactions are allowed to read changing data that other transactions are yet to commit. This aspect makes it unsafe as data is dynamically changing and the transaction may base its decision on changing data. It is important to note that there is no guarantee that other transaction(s) may commit (it/they can also rollback).
- Also, note it only allows READ of uncommitted data not update of uncommitted data.

3. READ COMMITTED
- As name suggest, under this mode, transactions are allowed to read committed data. Once transaction commit data it is immediately made visible to the other transactions. Since the transaction has committed, other transactions accessing it can make changes to the said data.
- As we can see below even though data has been updated by t1 it is not yet reflected on t2 since the transaction is not yet committed. t3 is blocked too since it is trying to modify the same set of rows.
- Once t1 is committed, t2 sees the update data in same transaction. Given this behavior, this mode is also referred as NON-REPEATABLE-READ.

4. REPEATABLE READ:
Under this mode, a snapshot is taken during execution of the first select. Even if the other transactions continue to commit, same snapshot is used to serve the read-view creating repeatable-consistent-read.
b. Only read-view will use the said snapshot. If the transaction tend to modify/update things then it will use the updated/latest/committed view for the modification.
c. This is default mode in MySQL and normally helps servers most of the workload maintaining the needed parallelism.
d. Let’s understand this with an example below.
- All 3 transactions started at same time and t2 and t3 got the needed read-view.
- Now even if t1 has changed and committed row with id = 10, t2 continue to use the consistent read-view that is created during start of transaction.
- t3 too continue to use the same read-view but t3 also update the same row after t1 and it then start seeing and updated view post that.
- We may wondered why didn’t t3 use the same read-view that it created during start of transaction to service the last select. This is where the concept of snapshot comes into picture. Technically t3 is made to base on a state of data that exist when it started. During t3 tenure, if it changes the data then same is visible to itself.
- This may sounds bit complex so the next section helps to clarify it along with structures and methods use to achieve this behavior.

MVCC
MVCC stands for Multi-Version Concurrency Control. It helps define how the parallel running transactions access the changing data. Above section describes different ISOLATION mode. Last mode REPEATABLE READ is default and involves multiple structures to maintain it.
Let’s start with simpler table as listed below to understand how this is implemented internally in InnoDB.
CREATE TABLE `t` ( `id` int(11) DEFAULT NULL, `c` char(30) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB; insert into t values (10, ‘newark’), (11, ‘san francisco’), (12, ‘washington’);
- Table above has 2 visible fields (id, c) with pk based on id so there is no need of innodb generated row-id to maintain uniqueness.
- db-trx-id represent the transaction that inserted or last updated the said row. In this case all the said rows were inserted by same transaction with trx-id = x.
- db-roll-ptr is pointer to the last saved state of the said row. (valid only in case of update. In-case of insert it is NULL as there is no previous state).
- db-row-id comes into picture only if user has not defined primary key based on the defined visible field.
Types of transactions
There are 2 types of transactions:
- read-only transactions: transaction just read data (no modification).
- read-write transactions: these transactions are meant to modify real-data. At start, all transactions are read-only, first update (INSERT or UPDATE) will move the transaction from read-queue to read-write queue.
Booting up a Transaction
There are 2 types of transactions:
- When a transaction starts for first time it will be placed in a read-only list assuming it to be read-only transaction.
- When transaction first accesses the data (SELECT) a read-view is created and get assigned to a transaction. In section below we will see how this read-view is computed.
- When transaction updates the data, changes are done to the table (in InnoDB clustered index) and previous version of the data is cached in what InnoDB referred as undo/rollback segment. Reference to this is cached in db-roll-ptr. Query can then access the old version of the row by traversing the chain. Each update is also tagged with the trx-id that modified the said row. (again we will see in the section below how his tagging helps).
- Transaction can continue to modify more that one data-row or data objects/tables.
- If in meantime, other independent transaction has modified un-related rows and this transaction tend to re-read these rows (first read was done during initial select) then transaction will continue to show the old copy that it has seen during initial select.
- If this read involves rows that transaction just modified above then updated value only for those rows are shown.